p3ml.github.io
Impulses for the Panel: The Open Science Publishing Flood and Collaborative Authoring
Grey Literature as Result of the P3ML Project (Some Contribution to the Flood and Means to Navigate it)
The project P3ML funded by the Ministry of Education and Research of Germany (BMBF) under grant number 01/S17064 offered student labs with a strong focus on the practical aspects of Machine Learning. Furthermore, it produced a variety of teaching materials. These were published on different platforms:
Jupyter Notebooks
All our notebooks have been published at GitHub. For ease of access we created an explicit entry page at https://p3ml.github.io. While GitHub is great for storing, sharing and versioning the notebook file, it does not display all its content correctly. To see all elements as they are meant, you may use nbviewer. There are even free services like Binder that allow to work interactively with notebooks stored at GitHub.
| Screenshots of the “Minimum Enclosing Ball” notebook as displayed by GitHub, nbviewer and Binder |
|---|
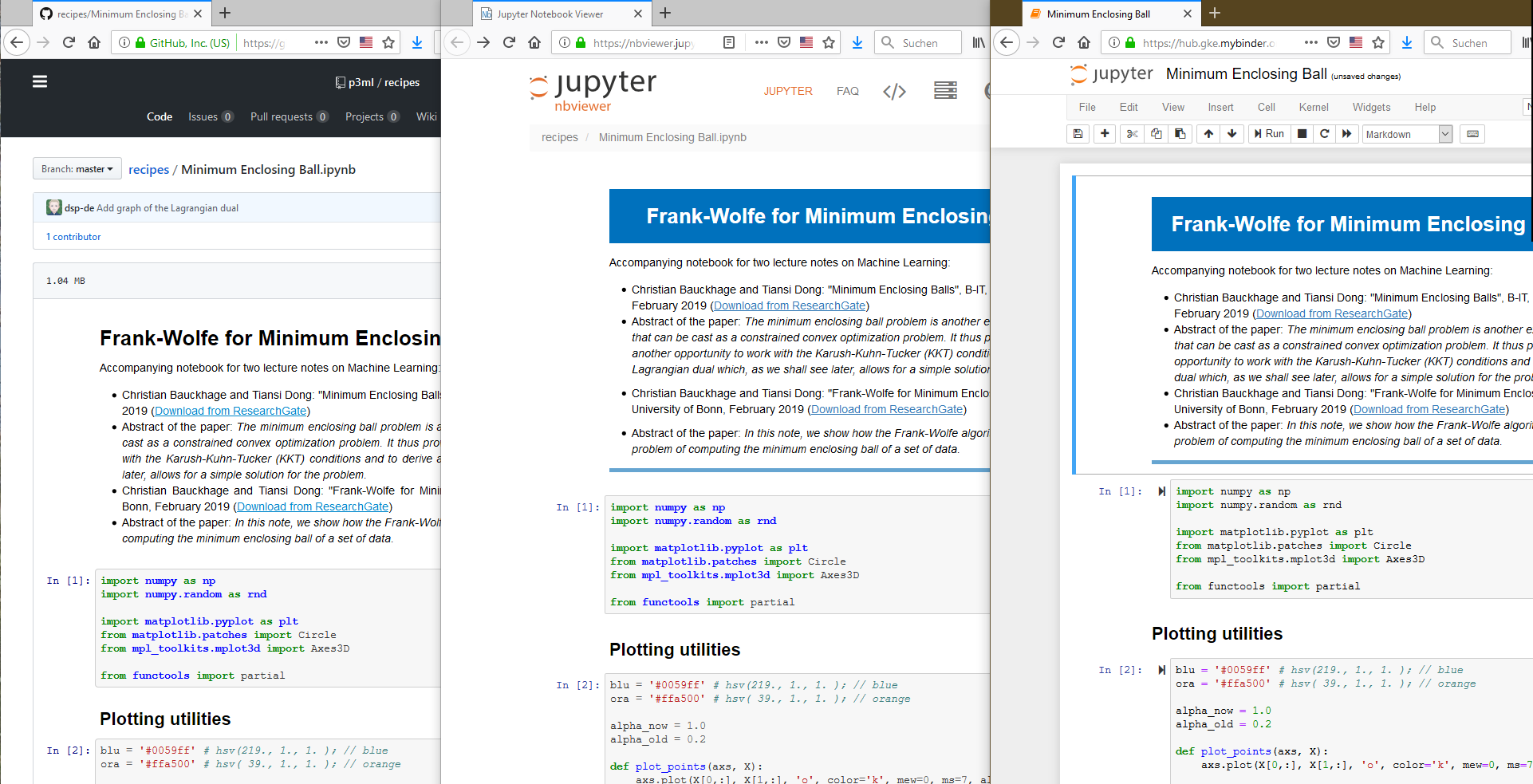 |
A notebook consists for cells that may contain formatted text (Markdown, HTML, LaTeX), code (most often Python, might include data) and results from previous runs including visualizations. When the user executes a code cell, the code is send to a process in the background (“the kernel”), executed and the result integrated into the notebook right below the code cell.
Elements of Explanation in Jupyter Notebooks
- You may collocate your formulas in mathematical notation with the executable implementation. Examples:
- You may combine different visualizations of the same problem. Example:
- Keep the implementation of the central algorithms almost free of visualization code by passing a visualization callback function. Examples:
- Illustrate a space of problems / models / solutions by giving a
variety of cases. Examples:
- Implementation variants to Ordinary Least Squares produce the same result
- Different damping factors for Regularized Least Squares may improve but as well distort the result
- A variety of Gaussion Mixture Models generated from the same three Gaussian Distributions
- Impact of different initializations on the Expectation Maximization Algorithm
- Finding the Minimum Enclosing Ball for different point sets*
- Variations of an ANN in depth, size and activation function
(*) Shown during the talk.
On Navigating the Flood
During the project with covered some technology that could be helpful to navigate the Open Science Publishing Flood.
One lab experimented with Latent Dirichlet Allocation for Topic Mining (Blei, D. M., Ng, A. Y., Jordan, M. I. (2003). Latent Dirichlet Allocation. Journal of Machine Learning Research, 3, 993–1022. https://dl.acm.org/citation.cfm?id=944919.944937). Which resulted in another set of notebooks. The actual lab worked on data that we can not publish so the published notebooks took a separate source: Answers of deputies of the Deutsche Bundestag at abgeordnetenwatch.de. The last notebook of this section shows the mined topics as wordclouds that give a (surprisingly?) good impression of the topics.
There are already ready made solutions for topic mining. For example https://www.hypershelf.org from https://inphoproject.org. Another nice component is https://github.com/bmabey/pyLDAvis. There are more. In the lab we had the impression that the evolution of topics over time is especially interesting (not yet transferred to the abgeordnetenwatch.de data set).
Two further labs experimented with the N-Ball approach that combines state of the art word-embeddings into vector spaces (allowing calculations like “king” - “man” + “woman” = “queen”) with concepts hierarchies as codified through WordNet. The students transferred the approach to different languages, often their mother tongue.
Literature about Jupyter Notebooks
- Daniel Speicher, Tiansi Dong, Olaf Cremers, Christian Bauckhage, Armin B. Cremers: Notes on the Code Quality Culture on Jupyter (Notebooks), 21. Workshop Software-Reengineering & Evolution (WSRE) 2019, Bad Honnef, Germany (preprint, slides, improved slides for another workshop)
- João Felipe Pimentel, Leonardo Murta, Vanessa Braganholo, Juliana Freire: A Large-scale Study about Quality and Reproducibility of Jupyter Notebooks, MSR 2019, Montreal, Canada (details)
- Rule A, Tabard A, and Hollan J. (2018) Exploration and Explanation in Computational Notebooks. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI’18). ACM Press, New York, NY. https://doi.org/10.1145/3173574.3173606. (https://www.youtube.com/watch?v=trlfzLyDI6U)
- Adam Rule, Amanda Birmingham, Cristal Zuniga, Ilkay Altintas, Shih-Cheng Huang, Rob Knight, Niema Moshiri, Mai H. Nguyen, Sara Brin Rosenthal, Fernando Pérez, Peter W. Rose:
- Ten Simple Rules for Reproducible Research in Jupyter Notebooks, Arxiv 2018, https://arxiv.org/abs/1810.08055
- Ten simple rules for writing and sharing computational analyses in Jupyter Notebooks, PLoS Comput Biol 15(7): e1007007. https://doi.org/10.1371/journal.pcbi.1007007
- Mary Beth Kery, Marissa Radensky, Mahima Arya, Bonnie E. John, and Brad A. Myers. 2018. The Story in the Notebook: Exploratory Data Science using a Literate Programming Tool. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems (CHI ‘18). ACM, New York, NY, USA, Paper 174, 11 pages. DOI: https://doi.org/10.1145/3173574.3173748, (https://www.youtube.com/watch?v=bmLUcnu1Qi8)
Presentations
- Volodymyr Kazantsev, Kateryna Nerush: Clean Code in Jupyter Notebooks, PyData 2017 Berlin (https://www.youtube.com/watch?v=2QLgf2YLlus, https://de.slideshare.net/katenerush/clean-code-in-jupyter-notebooks)
- Joel Grus: I Don’t Like Notebooks, JupyterCon 2018, (https://youtu.be/7jiPeIFXb6U, https://twitter.com/joelgrus/status/1033035196428378113)